「人体の内外表面形状すべてをリアルタイム計測するシステム」







技術紹介
![]()
![]()
![]()
深層学習を利用した能動ステレオ法
我々は,単一のパターンを投影する超小型の投光器を内視鏡に追加することで, アクティブステレオ法による3次元内視鏡を開発してきた. アクティブステレオ法における中心的な問題は, 観測画像とパターンとの対応付けを行うことである. そのため,観測画像からパターンの特徴を 抽出する必要がある. 内視鏡画像では,画質の制限や,対象組織の表面下散乱などがあるため, パターンの特徴の抽出の安定性が問題になる.
我々は,アクティブステレオ法におけるパターン抽出を安定的に行うために, 深層学習によって格子状パターンから特徴を抽出する手法を提案した. 提案手法では,CNNの一種であるU-Netを観測画像に適用することで, 画像中の格子パターンのグラフ構造と, 各格子点における特徴コードの抽出を行う. 提案手法の採用により, 既存手法である確率伝播法による格子パターン検出と比較して, パターン抽出の安定性が大幅に向上することが確認された(図1). また,3次元計測の安定化により, 内視鏡を動かしながら動画像を撮影することで, 奥行き画像を連続計測し,広範囲の形状計測を実現することができた(図2).

図1: がん試料へのパターン投影画像からの格子とコードの検出結果。(a): 試料の外観. (b) キャプチャ画像. (c) 水平線検出のU-Net出力. (d) コード検出のU-Net出力. (e)抽出された格子構造とコード(誤り率4.5%). (f) 既存手法で抽出された格子構造とコード(誤り率18.6%) (g) 再構成された三次元形状.
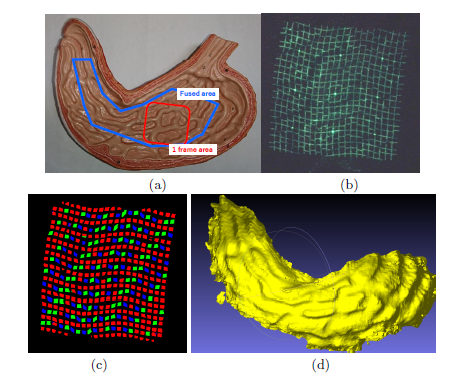
図2: 胃のファントムモデルを計測した例. (a)ファントムモデルの外観. (b)(a)の赤い矩形領域の単一キャプチャ画像. (c)(b)の格子とコード検出結果。 (d)複数の計測結果を融合した形状((a)の青い多角形の領域).
3次元内視鏡のためのHDR画像処理
内視鏡診療において,腫瘍のサイズは,治療のための重要情報である. しかし,その計測は,内視鏡用メジャーや,あるいは目視による推定で行われており, 時間がかかったり,あるいは人的要因による推定誤差が生じる可能性があった. このため,簡単に利用でき,かつ正確な,内視鏡による対象サイズの計測方法が求められている. 我々は,パターン投光器を内視鏡に追加することで, アクティブステレオ法による3次元内視鏡を開発してきた. これまでのシステムの欠点として, 投光器の焦点深度が浅いこと,光源の光量の利用効率が悪いこと, 対象となる生体組織の表面下散乱によるパターンのボケ, カメラ露出調整の困難さやハイライトの影響による 観測画像の局所的な白飛びや黒つぶれなどの問題点があった.
我々は,撮影画像上の局所的な白飛びや黒つぶれに対処するために, ハイダイナミックレンジ(HDR,High Dynamic Range)画像合成を利用する. HDR画像合成を行うには露出の異なる複数枚の画像を要する. しかし一般的な内視鏡は露出を変化させながら撮影を行うことができない. そこで,提案システムでは,投光器から照射する構造化光を 周期的に明滅させることで 段階的に露出の異なる画像群を得る. これにより,既存内視鏡のカメラでHDR画像生成を行うことが可能である.
HDR画像合成を行うには多段階露出画像の取得を要するが,一般的な内視鏡では露出を変化させながら撮影を行うことができない.そこで本研究では,被写体に投影する投光パターンを明滅させることでカメラに入り込む光量を調節し多段階露出画像を得る. 内視鏡カメラは被写体を映像として記録するため,撮影時はシャッターの開閉を一定周期で繰り返す.シャッターの開閉周期に対して異なる周期で投光器を明滅させることにより撮像素子に入り込む光量が1フレームごとに変化し,段階的な露出で画像を記録することができる. 図1に投光器の明滅周期がシャッター開閉周期よりも長い場合の露光時間の変化の例を示す.投光器を明滅させるために任意の周波数で信号を発生させるファンクションジェネレータを投光器に取り付ける.信号が等間隔の矩形波で送出されることによって投光器から発せられるパターンが等間隔で明滅する. 例えば30Hzでシャッター開閉を繰り返す内視鏡カメラに対して26Hzで投光器を明滅させると約8フレーム周期の段階的に異なる露出画像が得られる(多重露光)ので,これを用いてHDR画像合成を行う. この手法により,パターンを投影した画像の白飛びや黒つぶれを抑え,3次元復元の安定性を高めることに成功した。
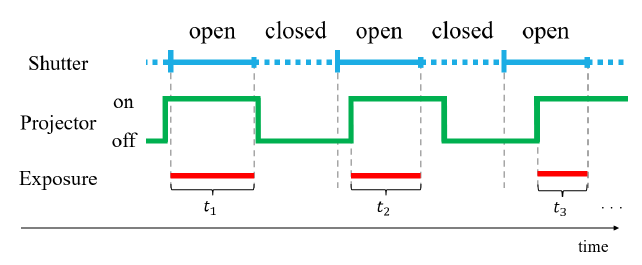
図1:カメラ露光時間とパターン変調の関係:ti 露光時間
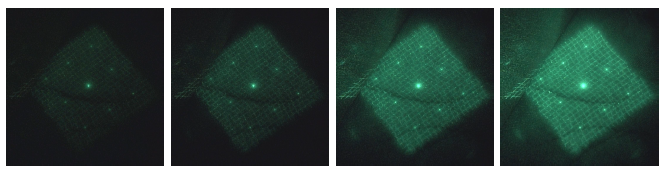
図2:多重露光された画像

図3:元画像と,HDR 画像の処理結果の比較. (a)元画像. (b)HDR 画像をトーンマップした画像. (c) 元画像における白飛び箇所の可視化(赤: 輝度値が255 の 部分,黄: 輝度値が235 以上の部分). (d) トーンマップ画像における白飛び箇所の可視化. (e) (a)の3次元復元結果.(f) (b) の3次元復元結果.
テクスチャ復元
固定パターンを投影する3次元スキャナは、その有効性から現在も広く用いられている。
この方式を用いる際には、対象物体をプロジェクタの光のみで照らすので、対象物体の自然な表面のテクスチャを取得することができなくなるという問題がある。そこで、我々はプロジェクタの投影する固定パターン画像を除去し、元の自然なテクスチャを復元するためのシステムを開発している。
その方法は、三次元形状の計測を行う前に、静止させた物体からパターンを投影したが画像と投影していない画像を取得する(図1)。この両画像を用いて、パターンと元の模様との対応関係を調べるための辞書を作成する。この辞書は、入力画像を小さな領域(3×3または9×9)に分割し個別に格納しておく。そして、対象物体の三次元形状を計測した後に、計測中に取得したパターンつきの画像と辞書に含まれる小領域を比較することで、物体本来の模様を復元する(図2)。
対応関係を探索する際には、誤対応を最小限にするためにregularizationを行う。この処理において、各小領域の境界がスムーズにつながるような候補が選ばれるような工夫を行った。その工夫は、Belief Propagationアルゴリズムを適用することで、辞書から復元対象の画像と最も一致する画像を選択する。これらの工夫により、ノイズやアーティファクトの少ない復元画像を得ることに成功した。しかし、高周波成分の多い固定パターンの場合 、元のパターンが残ってしまうという問題がある。この問題を解決するために、解像度の異なる2つの辞書(3×3および9×9)を用いて、階層的にテクスチャ復元を行う方法を適用した。この方法ではまず、解像度の荒い辞書を用いてテクスチャ復元を行うい、そのうえで解像度の細かい辞書を用いて再度復元を行うことで、高周波成分に対する問題を解消することが出来た(図3)。
われわれの提案する手法を用いることで、Kinectなどの既存のセンサーに比べて、より高精度かつ高密度にテクスチャ付の三次元形状取得することに成功した。
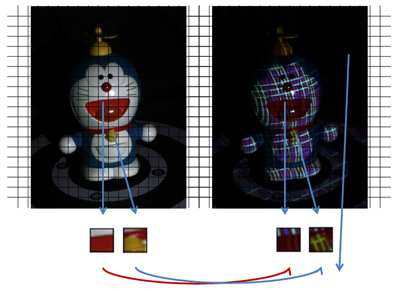
図1
辞書作成のための入力画像と対応領域

図2
辞書に含まれる小領域の一例

図3
テクスチャ復元の結果
Facial Motion Tracking
■提案手法の概要
人間の表情動作を対象としたモーションキャプチャでは,表皮の変形が複雑であり、変形の追跡が難しいという問題がある。そこで,多くの顔モーションキャプチャシステムでは動きを追跡するためのマーカを設置する手法が主流であった.しかしこの方法には、マーカの設置に要する手間やマーカの設置が困難な動作が取得できないという問題があり、マーカレス顔モーションキャプチャが求められている.そこで、顔を4種類の器官(口,鼻,目,頬)とノイズ領域にあらかじめ分類し,各器官毎に形状の変形を求めることで,誤対応の少ない顔モーションキャプチャを実現するためのシステムを提案している.提案システムは次に示す4段階の処理から構成される(図1).
図1
図2
(a)顔形状の取得:
既存の3次元形状計測手法により,顔形状を表す3次元点群データ取得する.
また,その点群データに対応する3角形メッシュおよび深度マップを取得する.
(b)顔形状の部位識別:
顔形状データから,鼻,口,目,頬の4種の部位およびノイズ領域を識別する.この識別にはRandom Forestを用いる(図2).
(c)各部位の変形追跡:
(b)で識別した各部位を表す領域の時系列上での変化をNon-rigid Registration手法により追跡する.追跡の際には,入力データの第1フレームにおける形状データを他のフレームの形状にフィッティングさせる.
(d)変形の統合:
(c)では,各部位毎に独立して形状変形を追跡しているので,部位の境界付近では動きが不連続となる.そこで,Radial Basis Functionに基づく3次元形状変形手法に基づき各部位の動きを統合する.
以上の処理により,時間的に連続ではない3次元形状データから,第1フレームの連続的な変形という形式で,顔の動きを取得できる.
■システムの評価
提案手法の精度を評価するために,顔を手で叩く動作(Slap),笑顔の表情を作る動作(Smile),縦方向に縮めた顔を大きく伸ばす動作(Stretch),および一般物体に対する適用例としてボールを握る動作(Grip)の4種の動作に含まれる誤差を計測した(図3).
図4、従来の変形追跡手法と提案手法との比較結果を示す。この結果から,Slap,StretchおよびGrip動作では,従来手法に比べ平均誤差を約13%から45%$削減することができた. また、特に変形が大きいSlap動作の口元に着目し,図5の上部に示す5点に関して誤差を求めた結果からも提案手法は従来手法に比べて同一点を精度よく追跡していることが分かる.
図3
変形追跡結果 (a)Slap、(b)Smile、(c)Stretch、(d)Grip
図4
追跡精度の比較
図5
口周辺の変形追跡結果 (a) Ground truth、(b)提案手法、(c)L2+TPS
顔モーションキャプチャシステムのデモムービー
レンダリング
スキャナとカメラから構成される3次元スキャナシステムは、高精度でありかつ安価であるという利点がある。このシステムから出力されるデータは、3次元空間上の位置と時間に伴う変化という4次元の情報となる。このような方法により計測した、物体の表面形状をあらわすデータは一般的に膨大なサイズとなり、データ量の削減が必要とされている。
特に、データを圧縮する方法は、データの保存のみならず、ネットワークを通じた転送においても重要である。また、このような膨大なデータ量を高速にレンダリングする方法も求められている。
特に、ハイスピードスキャンを行う際には、軽量で高速な表示手法が必要とされており、様々な研究が行われている。Surfel splattingは代表的なレンダリング手法の1つであり、一定の大きさをもった点を曲面の代わりに描画することで、レンダリングを高速化している。一方、Voxelによる形状表現も有効な形状表現手法の1つとして、様々な研究が行われている。特に、階層化されたVoxel表現は、level-of-detailを実現する上でも有効に働く。このVoxelの階層化には、Octreeを用いる方法が一般的である。
我々の研究では、GPUの特徴を考慮したsurfel およびvoxelのレンダリング手法を提案している。提案手法では、GPUの持つ機能の1つであるgeometry shaderを利用することで、効率的にsurfel およびvoxelから元の物体に近い形状を自動生成する。surfelからの形状生成を全てGPU上で行うことで、CPUで行う場合に比べてはるかに高速に形状生成を行うことが出来る。その際に、元の点群のもつ情報を保存するように形状生成を行うことで、シーンを切り替えた際も高速にレンダリングすることを可能にした。一連の手法において、前処理などの特別な処理を行う必要の無い実装を行うことで、既存の3次元形状計測手法に対して容易に機能を付加することができる手法を構築できた。さらに、surfel およびvoxelのもつ疎な空間を効率的に扱う手法を適用し、高速性を高めることに成功した。

図1
Surfelによる点群データのレンダリング例: a) 一般的な手法, b)深度情報を除外した配置, c) two-passレンダリング(可視判定),d) two-passレンダリング(陰影付けあり), e) Surfel の拡大による表現 f) 提案手法による拡大表現
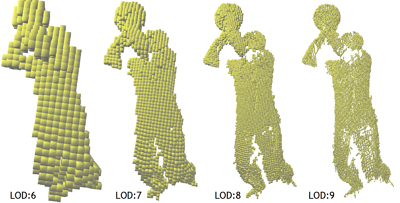
図2
Lelev-of-Detailに基づくVoxel表現

図3
SurfelとVoxelによる表現の比較(投球動作)

図4
SurfelとVoxelによる表現の比較(リフティング)
![]()